Ground truth in AI: how assumptions can make or break your model
Ground truth in AI: how assumptions can make or break your model
“Data is the new gold” and “data is the new oil” are phrases you hear more and more often in the world of artificial intelligence. They highlight how essential data is for training intelligent systems. But just like crude oil only gains value after refinement, the same applies to data: unrefined data is essentially worthless.
Within the PUW! research project at Howest University of Applied Sciences, we recently conducted a study on stress detection. By linking an AI algorithm to heart rate data from a Polar 360 wearable, we aimed to detect when someone is experiencing high stress. The study clearly illustrates how complex it is to reliably label data for AI training. Fortunately, the laboratory team at AZ Groeninge Hospital supported us in this process.
Main section
Quick facts
/
Also for data, quality outweighs quantity
/
Labeling data for AI can be complex but is always essential
/
AI itself can support the data labeling process
/
In the PUW! study, we combined cortisol measurements and experimental manipulation for reliable stress labeling
The quest for a reliable ground truth
Many AI models rely on supervised learning: you provide the system with hundreds or thousands of examples, each labeled—in our case “stress” or “no stress”—and the model learns to recognize patterns on its own. The challenge, however, is that assigning these labels is not always straightforward.
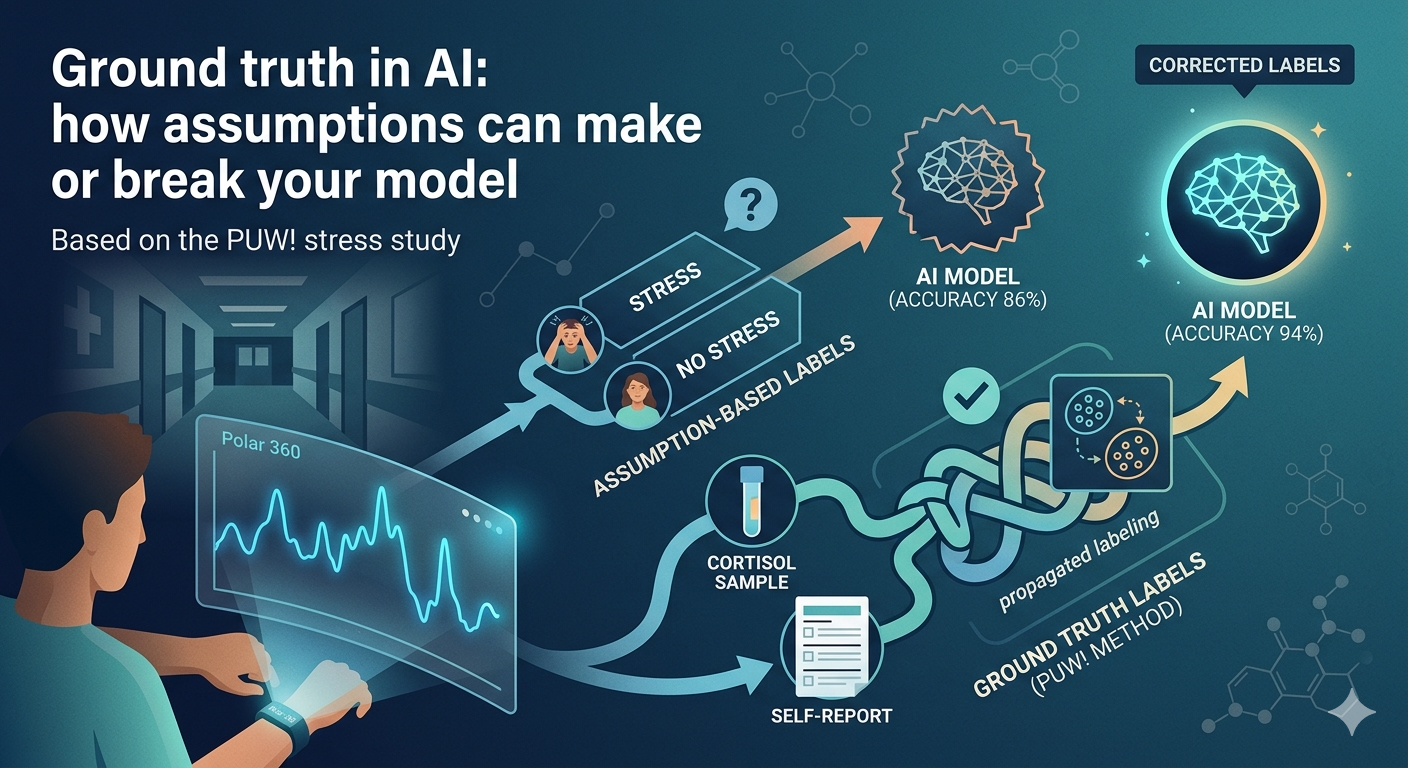
Stress is not directly observable or easily measurable. That is why we opted for a controlled laboratory setup using the Trier Social Stress Test, a method specifically designed to induce stress. We invited 30 employees from Howest and AZ Groeninge, each of whom went through three phases individually: a resting phase, a stress phase, and a recovery phase.
On paper, this seems simple: during the stress phase, everyone experiences stress, and during the other phases, they do not. In practice, however, this assumption did not hold. Some participants were already nervous during the resting phase, while others remained surprisingly calm during the stress test.
This demonstrates how misleading assumptions can be. If you train a model on incorrectly labeled data, it will learn the wrong patterns.
To introduce more objectivity, we collaborated with AZ Groeninge Hospital to measure cortisol levels through saliva samples. Cortisol is widely regarded as a reliable indicator of stress. However, it also has limitations as a ground truth. First, cortisol responds with a delay: it typically peaks 15 to 20 minutes after a stress event. Second, translating cortisol values into binary labels is inherently arbitrary. If a 20% increase indicates stress, what about someone with a 19% increase?
Why not simply ask participants whether they felt stressed? We did, but self-reporting has its own limitations. People differ in how they report experiences, and some may hesitate to admit they were stressed.
The solution: “label propagation”
The solution lay in a technique called label propagation (implemented in the python scikit learn package). This approach combines multiple data sources to achieve more accurate labeling. First, we distinguished between certain and uncertain data. Data points where both the experimental phase and cortisol measurements aligned were considered reliable.
For the uncertain cases, we applied a clustering algorithm. This algorithm grouped physiologically similar moments without prior knowledge of whether they represented stress. These clusters were then linked to the reliable data to assign labels.
The results were striking. A quarter of the data labeled as “stress phase” turned out not to contain stress. Additionally, a small portion of the resting phase—especially in the first minutes—did show clear stress signals. This again highlights how misleading simple assumptions can be.
By assuming that everyone was relaxed during the resting phase and stressed during the stress phase, we introduced incorrect labels in more than 10% of the total dataset. This naturally confused the model. In many cases, the heart rate was low, yet the model was told the person was stressed. Once we corrected the labeling, the performance of the AI model improved significantly: accuracy increased from 86% to 94% when detecting stress in new individuals.
Bottom section
What this means for the future of AI
This stress study illustrates a broader challenge in artificial intelligence. It is often assumed that more data automatically leads to better performance. In reality, the quality of that data—and the assumptions behind it—are just as important.
Establishing a reliable ground truth requires deep domain expertise, careful methodology, and the integration of multiple data sources. It also requires critical reflection on assumptions that are often taken for granted.
For organizations and researchers, this means that investing in data quality is essential. Poor data can not only undermine models but also lead to incorrect decisions in AI-driven applications.
The future of AI will not be defined by larger datasets alone, but by smarter, cleaner, and better-understood data.
A special thank you to the teams at Polar and AZ Groeninge Hospital in Kortrijk for their invaluable support in this study.
Contributors
Authors
/
Pieter Verbeke, AI Researcher
Want to know more about our team?
Visit the team page
Last updated on: 3/18/2026
/


